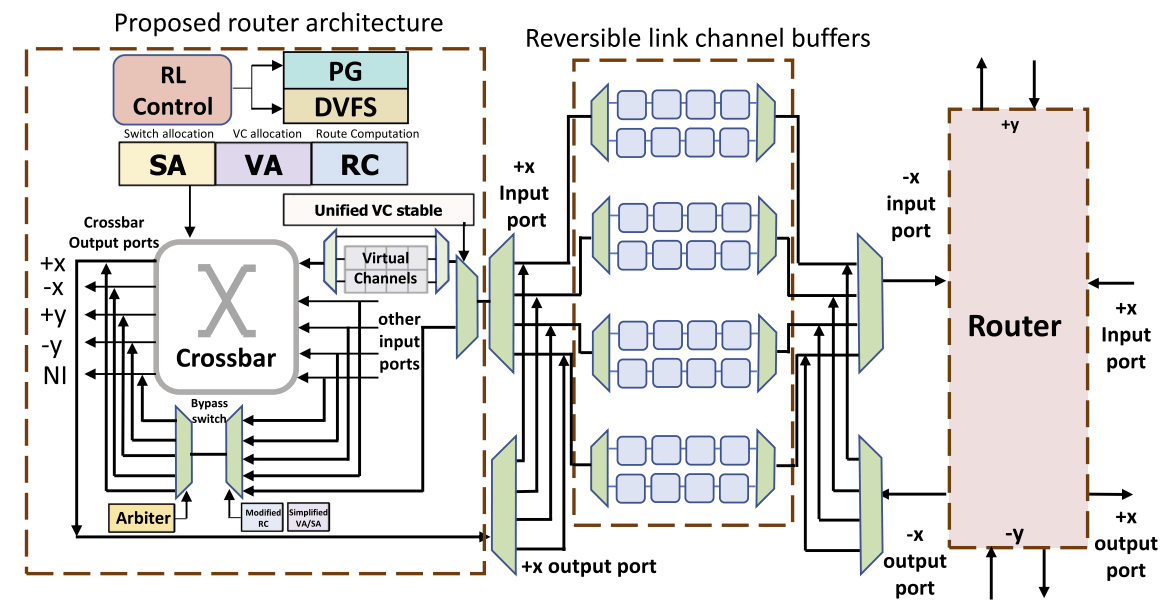
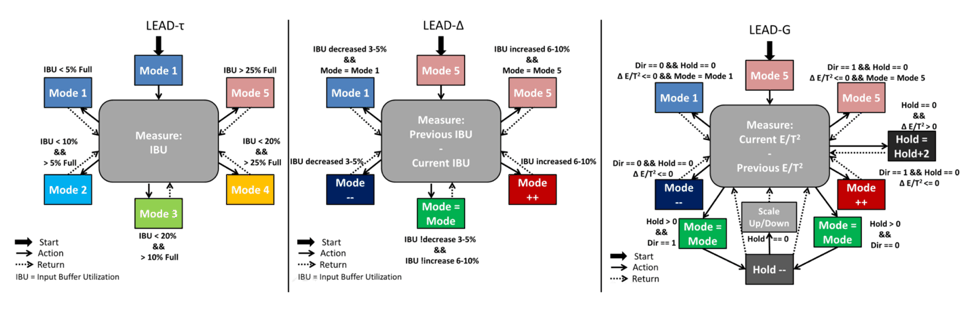
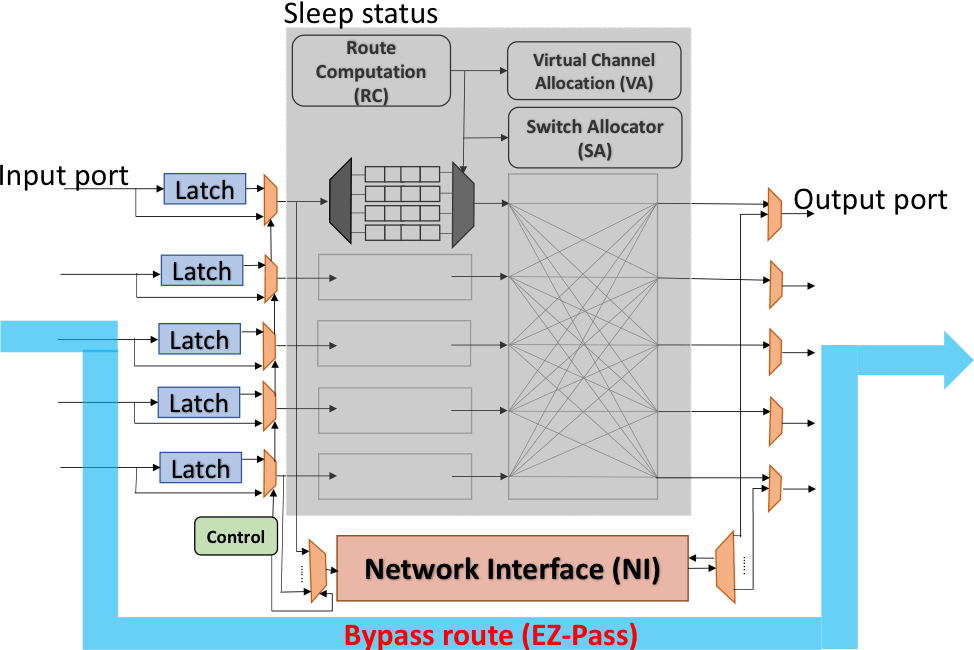
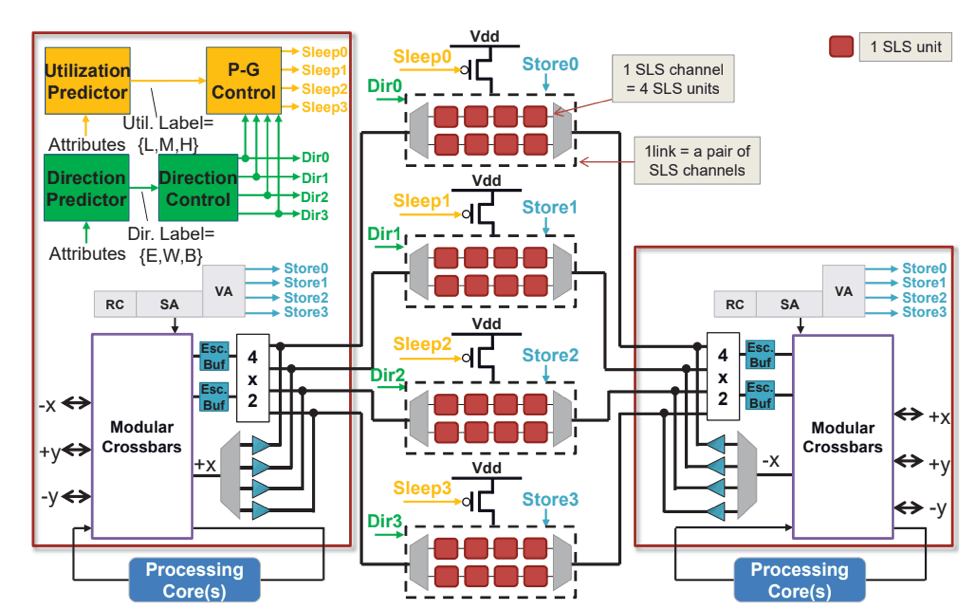
Over the last decade, Moore’s Law has slowed, while Dennard Scaling has ended. The end of voltage scaling has made power dissipation the fundamental barrier to scaling computing performance on all platforms, from mobile devices to embedded systems, laptops, servers, and datacenters.
This challenge, often called the power wall, is seen across the board. To meet power challenges, recent research has proposed various low-power techniques. Power-gating, for example, is an effective technique that powers off the under-utilized components to reduce static power consumption.