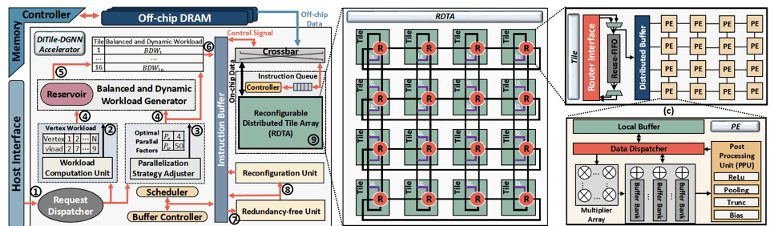
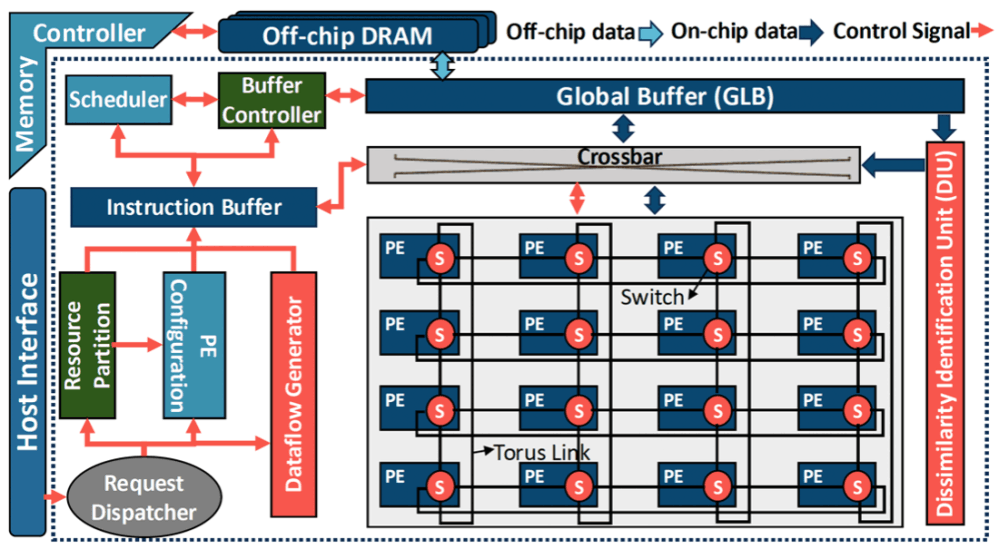
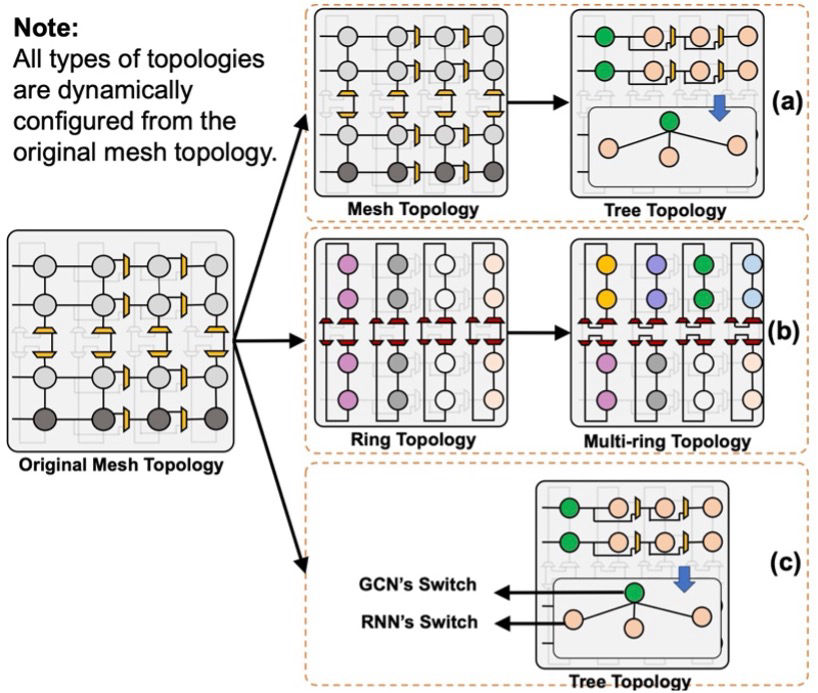
As the size of both static and dynamic real-world graphs increases exponentially, graph-based processing and neural networks present significant challenges for conventional hardware platforms due to their irregular memory access patterns and high computational demands, often leading to substantial degradation in performance and energy efficiency. To address these issues, our research focuses on designing domain-specific accelerators that can efficiently support both static and dynamic graph workloads, with optimized performance and energy efficiency. Our research covers several critical areas: (1) Scalable dataflow architectures designed for irregular computation patterns, (2) Dynamic and static workload partitioning strategies to ensure balanced execution, (3) Intelligent memory systems that enhance data locality, reuse, and bandwidth utilization, and (4) Fine-grained parallelism and hardware-level optimizations to reduce latency and computational redundancy. We develop accelerator designs on FPGA and ASIC platforms, leveraging algorithm-hardware co-design principles to maintain high accuracy while pushing the limits of throughput and energy efficiency.