
Generative adversarial networks (GANs) have emerged as a powerful solution for generating synthetic data when the availability of large, labeled training datasets is limited or costly in large-scale machine learning systems. Recent advancements in GAN models have extended their applications across diverse domains, including medicine, robotics, and content synthesis. These advanced GAN models have gained recognition for their excellent accuracy by scaling the model. However, existing accelerators face scalability challenges when dealing with large-scale GAN models. As the size of GAN models increases, the demand for computation and communication resources during inference continues to grow. To address this scalability issue, this article proposes Chiplet-GAN, a chiplet-based accelerator design for GAN inference. Chiplet-GAN enables scalability by adding more chiplets to the system, thereby supporting the scaling of computation capabilities. To handle the increasing communication demand as the system and model scale, a novel interconnection network with adaptive topology and passive/active network links is developed to provide adequate communication support for Chiplet-GAN. Coupled with workload partition and allocation algorithms, Chiplet-GAN reduces execution time and energy consumption for GAN inference workloads as both model and chiplet-system scales. Evaluation results using various GAN models show the effectiveness of Chiplet-GAN. On average, compared to GANAX, SpAtten, and Simba, the Chiplet-GAN reduces execution time and energy consumption by 34% and 21%, respectively. Furthermore, as the system scales for large-scale GAN model inference, Chiplet-GAN achieves reductions in execution time of up to 63% compared to the Simba, a chiplet-based accelerator.
Sparse Convolutional Neural Network (CNN) training is well known to be time-consuming due to significant off-chip memory traffic. To effectively deploy sparse training, existing accelerators store matrices in a compressed format to eliminate memory accesses for zeros; hence, accelerators are designed to process compressed matrices to avoid zero computations. We have observed that the compression rate is greatly affected by the sparsity in the matrices with different formats. Given the varying levels of sparsity in activations, weights, errors, and gradients matrices throughout the sparse training process, it becomes impractical to achieve consistently high compression rates using a singular compression method for the entire duration of the training. Moreover, random zeros in the matrices result in irregular computation patterns, further increasing execution time. To address these issues, we propose a balanced sparse matrix convolution accelerator design for efficient CNN training. Specifically, a dual matrix compression technique is developed that seamlessly combines two widely used sparse matrix compression formats with a control algorithm for lower memory traffic during training. Based on this compression technique, a two-level workload balancing technique is then designed to further reduce the execution time and energy consumption. Finally, an accelerator is implemented to support the proposed techniques. The cycle-accurate simulation results show that the proposed accelerator reduces the execution time by 34% and the energy consumption by 24% on average compared to existing sparse training accelerators.
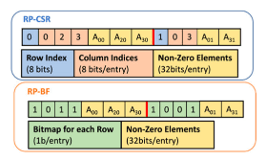
Approximation is an emerging design methodology for reducing power consumption and latency of on-chip communication in many computing applications. However, for training and inference of image classification models, existing approximate communication techniques achieve modest improvements in these metrics. In this paper, we propose an approximate communication technique to improve the efficiency of on-chip communications by exploring the error tolerance of the model during training and inference, resulting in better overall performance for the operations. This is achieved by taking advantage of three approximation opportunities, including quantization, contrast reduction, and matrix sparsification. The proposed approximate communication technique is implemented with quality control and data approximation techniques for quantization and contrast reduction during inference. The implementation also includes a dual-matrix compression method to further reduce the size of sparse matrices in on-chip communication. The combined effect of data approximation and compression reduces the number of flits in each data packet as well as the on-chip communication while maintaining excellent image classification accuracy for both training and inference. The detailed evaluation shows that compared to the state-of-the-art approximate communication technique, the proposed technique achieves 35% and 31% reduction in dynamic power consumption and network latency, respectively, for training. In terms of inference, the proposed technique reduces dynamic power consumption and network latency by 27% and 26%, respectively, with less than 0.99% accuracy loss.

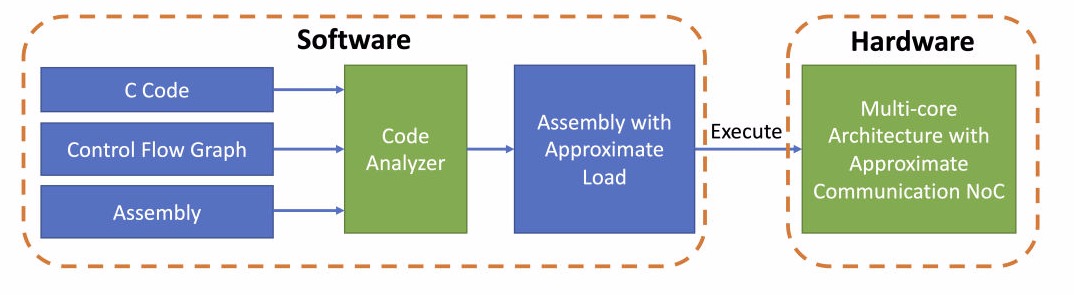
Current multi/many-core systems spend large amounts of time and power transmitting data across on-chip interconnects. This problem is aggravated when data-intensive applications, such as machine learning and pattern recognition, are executed in these systems. Recent studies show that some data-intensive applications can tolerate modest errors, thus opening a new design dimension, namely, trading result quality for better system performance. In this article, we explore application error tolerance and propose an approximate communication framework to reduce the power consumption and latency of network-on-chips (NoCs). The proposed framework incorporates a quality control method and a data approximation mechanism to reduce the packet size to decrease network power consumption and latency. The quality control method automatically identifies the error-resilient variables that can be approximated during transmission and calculates their error thresholds based on the quality requirements of the application by analyzing the source code. The data approximation method includes a lightweight lossy compression scheme, which significantly reduces packet size when the error-resilient variables are transmitted. This frame- work results in fewer flits in each data packet and reduces traffic in NoCs while guaranteeing the quality requirements of applications. Our cycle-accurate simulation using the AxBench benchmark suite shows that the proposed approximate communication framework achieves 36 percent latency reduction and 46 percent dynamic power reduction compared to previous approximate communication techniques.
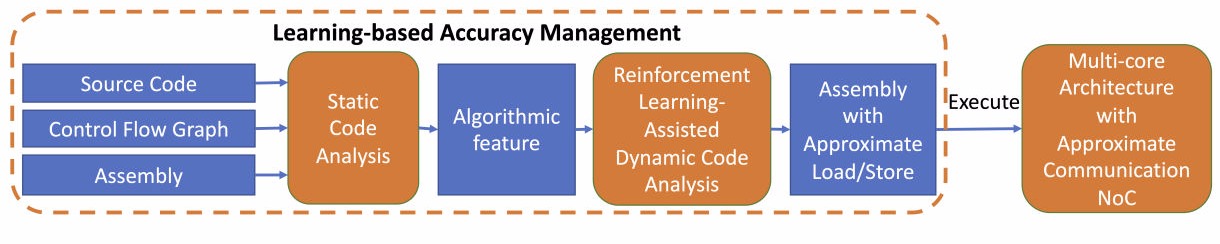
In this article, we explore application error tolerance and propose an approximate communication framework to reduce the power consumption and latency of network-on-chips (NoCs). The proposed framework incorporates a quality control method and a data approximation mechanism to reduce the packet size to decrease network power consumption and latency. The quality control method automatically identifies the error-resilient variables that can be approximated during transmission and calculates their error thresholds based on the quality requirements of the application by analyzing the source code. The data approximation method includes a lightweight lossy compression scheme, which significantly reduces packet size when the error-resilient variables are transmitted. This framework results in fewer flits in each data packet and reduces traffic in NoCs while guaranteeing the quality requirements of applications. Our cycle-accurate simulation using the AxBench benchmark suite shows that the proposed approximate communication framework achieves 62 percent latency reduction and 43 percent dynamic power reduction compared to previous approximate communication techniques while ensuring 95 percent result quality.

Department of Electrical and Computer Enginnering
School of Engineering and Applied Science
The George Washington University
800 22nd Street NW
Washington, DC 20052
United States of America
Ahmed Louri, IEEE Life Fellow
David and Marilyn Karlgaard Endowed Chair Professor of ECE
Director, HPCAT Lab
Email: louri@gwu.edu
Phone: +1 (202) 994 8241

AI Website Generator