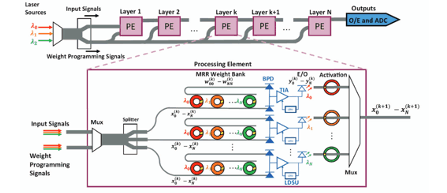
The convergence of edge computing and artificial intelligence requires that inference is performed on-device to provide rapid response with low latency and high accuracy without transferring large amounts of data to the cloud. However, power and size limitations make it challenging for electrical accelerators to support both inference and training for large neural network models. To this end, we propose Trident, a low-power photonic accelerator that combines the benefits of phase change material (PCM) and photonics to implement both inference and training in one unified architecture. Emerging silicon photonics has the potential to exploit the parallelism of neural network models, reduce power consumption and provide high bandwidth density via wavelength division multiplexing, making photonics an ideal candidate for on-device training and inference. As PCM is reconfigurable and non-volatile, we utilize it for two distinct purposes: (i) to maintain resonant wavelength without expensive electrical or thermal heaters, and (ii) to implement non-linear activation function, which eliminates the need to move data between memory and compute units. This multi-purpose use of PCM is shown to lead to significant reduction in energy consumption and execution time. Compared to photonic accelerators DEAP-CNN, CrossLight, and PIXEL, Trident improves energy efficiency by up to 43% and latency by up to 150% on average. Compared to electronic edge AI accelerators Google Coral which utilizes the Google Edge TPU and Bearkey TB96-AI, Trident improves energy efficiency by 11% and 93% respectively. While NVIDIA AGX Xavier is more energy efficient, the reduced data movement and GST activation of Trident reduce latency by 107% on average compared to the NVIDIA accelerator. When compared to Google Coral and the Bearkey TB96-AI, Trident reduces latency by 1413% and 595% on average.
Large-scale deep neural network (DNN) accelerators are poised to facilitate the concurrent processing of diverse DNNs, imposing demanding challenges on the interconnection fabric. These challenges encompass overcoming performance degradation and energy increase associated with system scaling while also necessitating flexibility to support dynamic partitioning and adaptable organization of compute resources. Nevertheless, conventional metallic-based interconnects frequently confront inherent limitations in scalability and flexibility. In this paper, we leverage silicon photonic interconnects and adopt an algorithm-architecture co-design approach to develop MDA, a DNN accelerator meticulously crafted to empower high-performance and energy-efficient concurrent processing of diverse DNNs. Specifically, MDA consists of three novel components: 1) a resource allocation algorithm that assigns compute resources to concurrent DNNs based on their computational demands and priorities; 2) a dataflow selection algorithm that determines off-chip and on-chip dataflows for each DNN, with the objectives of minimizing off-chip and on-chip memory accesses, respectively; 3) a flexible silicon photonic network that can be dynamically segmented into sub-networks, each interconnecting the assigned compute resources of a certain DNN while adapting to the communication patterns dictated by the selected on-chip dataflow. Simulation results show that the proposed MDA accelerator out-performs other state-of-the-art multi-DNN accelerators, including PREMA, AI-MT, Planaria, and HDA. MDA accelerator achieves a speedup of 3.6, accompanied by substantial improvements of 7.3×, 12.7×, and 9.2× in energy efficiency, service-level agreement (SLA) satisfaction rate, and fairness, respectively.
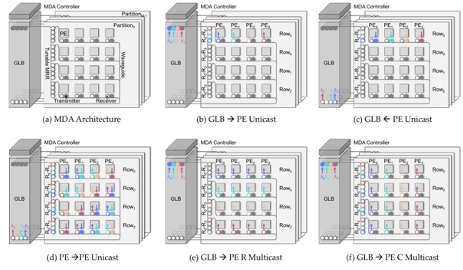
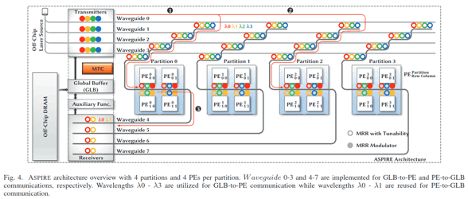
In shared environments like cloud-based datacenters, hardware accelerators are deployed to meet the scale-out computation demands of deep neural network (DNN) inference tasks. As conventional hardware accelerators optimized for single-DNN execution cannot effectively resolve the dynamic interaction of these inference-as-a-service (INFaaS) tasks, several multi-DNN hardware accelerators have been developed to improve the overall system performance while adhering to the constraints of individual tasks. Some of such multi-DNN hardware accelerators temporally schedule tasks by incorporating the preemption or load-balancing-based algorithm but suffer from resource underutilization because of unmanaged mismatch between resource demand and provision. Other multi-DNN hardware accelerators enable spatial colocation of tasks to improve resource utilization and system flexibility, but the irregular communication patterns between the fragmented resource partitions cannot be adequately supported by the metallic-based interconnects due to their rigidity and other inherent scaling limitations. We introduce a photonic multi-DNN accelerator named ASPIRE in this paper. The fundamental novelty of ASPIRE lies in the ability to adaptively create sub-accelerators for different tasks by assembling fine-grained resource partitions in the same architecture. Seamless communications between those fragmented resource partitions from a sub-accelerator are realized by exploiting photonic interconnects. Specifically, ASPIRE includes three novel designs: (1) a photonic network that can be adaptively partitioned into several sub-networks, each seamlessly connecting the fragmented resource partitions to construct sub-accelerators; (2) a dataflow that simultaneously leverages temporal and spatial data reuse opportunities within each resource partition and across several resource partitions, respectively; (3) an algorithm that allocates resource partitions at task granularity and derives optimal tile size and execution order at DNN layer granularity. Simulation studies show that A SPIRE outperforms other state-of-the-art multi-DNN accelerators, delivering 64% execution time reduction, 69% energy saving, 51% improvement in service-level agreement satisfaction rate, and 7.9× improvement in fairness.
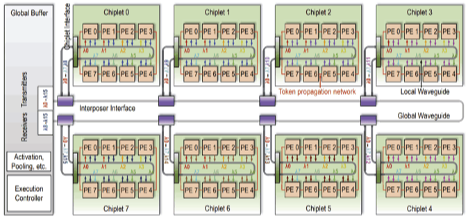
In pursuit of higher inference accuracy, deep neural network (DNN) models have significantly increased in complexity and size. To overcome the consequent computational challenges, scalable chiplet-based accelerators have been proposed. However, data communication using metallic-based interconnects in these chiplet-based DNN accelerators is becoming a primary obstacle to performance, energy efficiency, and scalability. The photonic interconnects can provide adequate data communication support due to some superior properties like low latency, high bandwidth and energy efficiency, and ease of broadcast communication. In this project, we propose SPACX: a Silicon Photonics-based Chiplet Accelerator for DNN inference applications. Specifically, SPACX includes a photonic network design that enables seamless single-chiplet and cross-chiplet broadcast communications, and a tailored dataflow that promotes data broadcast and maximizes parallelism. Furthermore, we explore the broadcast granularities of the photonic network and implications on system performance and energy efficiency. A flexible bandwidth allocation scheme is also proposed to dynamically adjust communication bandwidths for different types of data. Simulation results using several DNN models show that SPACX can achieve 78 percent and 75 percent reduction in execution time and energy, respectively, as compared to other state-of-the-art chiplet-based DNN accelerators.
Chiplet-based convolution neural network (CNN) accelerators have emerged as a promising solution to provide substantial processing power and on-chip memory capacity for CNN inference. The performance of these accelerators is often limited by inter-chiplet metallic interconnects. Emerging technologies such as photonic interconnects can overcome the limitations of metallic interconnects due to several superior properties including high bandwidth density and distance-independent latency. However, implementing photonic interconnects in chiplet-based CNN accelerators is challenging and requires combined effort of network architectural optimization and CNN dataflow customization. In this project, we propose SPRINT, a chiplet-based CNN accelerator that consists of a global buffer and several accelerator chiplets. SPRINT introduces two novel designs: (1) a photonic inter-chiplet network that can adapt to specific communication patterns in CNN inference through wavelength allocation and waveguide reconfiguration, and (2) a CNN dataflow that can leverage the broadcasting capability of photonic interconnects while minimizing the costly electrical-to-optical and optical-to-electrical signal conversions. Simulations using multiple CNN models show that SPRINT achieves up to 76 percent and 68 percent reduction in execution time and energy consumption, respectively, as compared to other state-of-the-art chiplet-based architectures with either metallic or photonic interconnects.
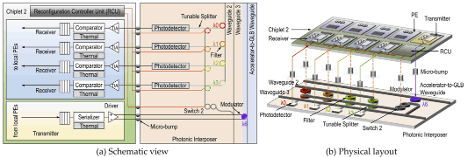
The complexity and size of recent deep neural network (DNN) models have increased significantly in pursuit of high inference accuracy. Chiplet-based accelerator is considered a viable scaling approach to provide substantial computation capability and on-chip memory for efficient process of such DNN models. However, communication using metallic interconnects in prior chiplet-based accelerators poses a major challenge to system performance, energy efficiency, and scalability. Photonic interconnects can adequately support communication across chiplets due to features such as distance-independent latency, high bandwidth density, and high energy efficiency. Furthermore, the salient ease of broadcast property makes photonic interconnects suitable for DNN inference which often incurs prevalent broadcast communication. In this paper, we propose a scalable chiplet-based DNN accelerator with photonic interconnects named A SCEND . A SCEND introduces (1) a novel photonic network that supports seamless intra- and inter-chiplet broadcast communication, and flexible mapping of diverse convolution layers, and (2) a tailored dataflow that exploits the ease of broadcast property and maximizes parallelism by simultaneously processing computations with shared input data. Simulation results using multiple DNN models show that ASCEND achieves 71% and 67% reduction in execution time and energy consumption, respectively, as compared to other state-of-the-art chiplet-based DNN accelerators with metallic or photonic interconnects.

Department of Electrical and Computer Enginnering
School of Engineering and Applied Science
The George Washington University
800 22nd Street NW
Washington, DC 20052
United States of America
Ahmed Louri, IEEE Life Fellow
David and Marilyn Karlgaard Endowed Chair Professor of ECE
Director, HPCAT Lab
Email: louri@gwu.edu
Phone: +1 (202) 994 8241

Website Builder Software