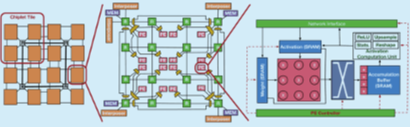
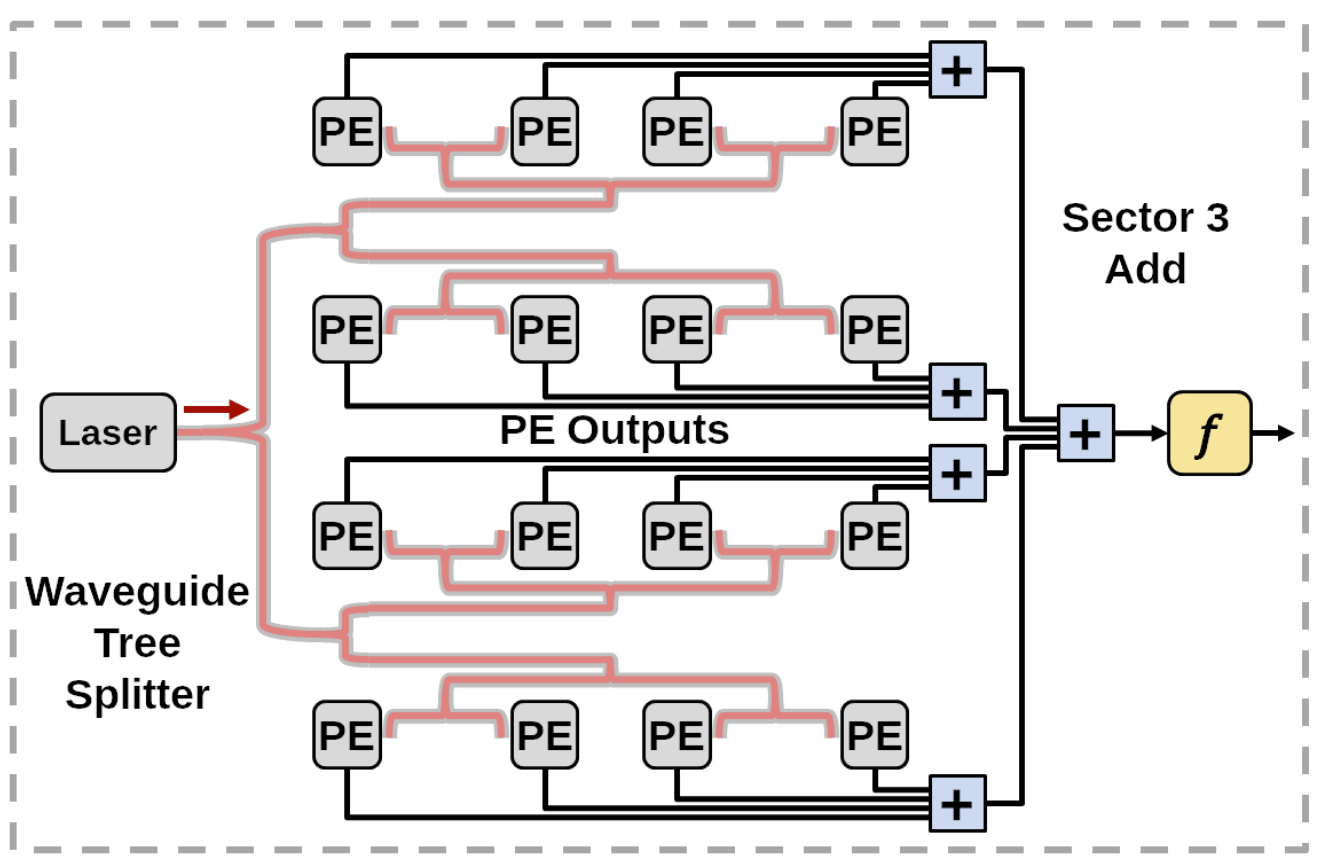
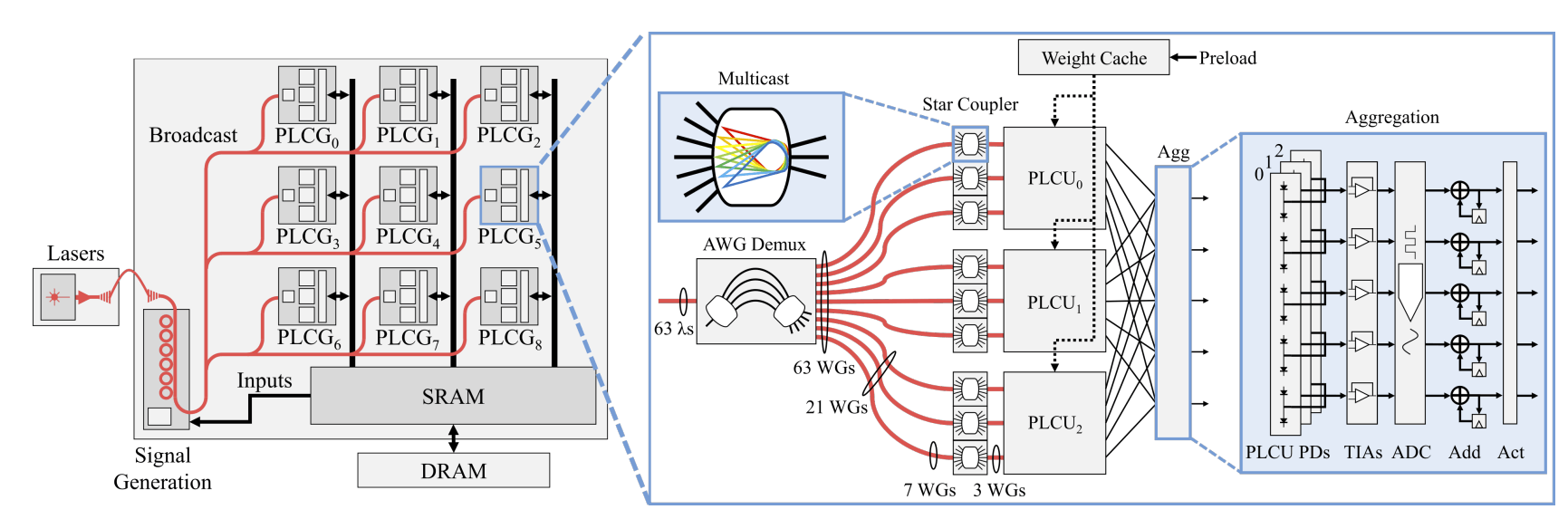
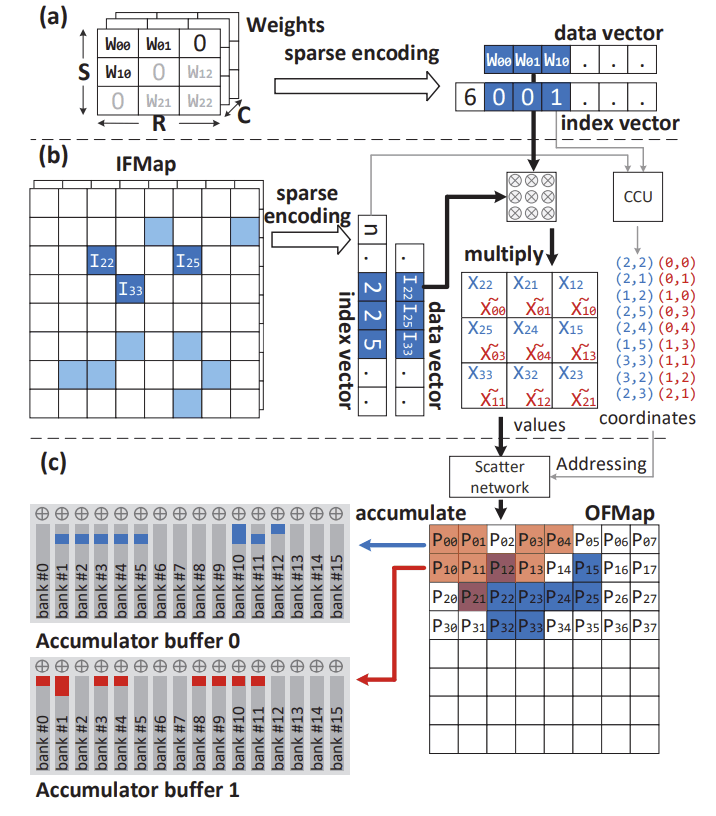
As machine learning models grow in complexity and scale, traditional monolithic chip designs struggle to meet demands for compute density, energy efficiency, and scalability. Our research focuses on chiplet-based accelerator designs that address these limitations while enabling scalable deployment of machine learning systems. Our research works targets the following key areas: (1) Custom interconnection networks that adapt to diverse traffic patterns from heterogeneous cores, (2) Silicon interposer-aware network designs for high-bandwidth, low-latency communication in chiplet systems, (3) Hardware-software co-design for optimizing machine learning (ML) inference and training across distributed compute fabrics, and (4) Scalable accelerator fabrics that maintain throughput under limited area and power budgets. By embracing the modularity of chiplet-based architectures and the specialization of machine learning accelerators, our goal is to create high-performance, energy-efficient, and scalable computing platforms for next-generation AI applications, from edge devices to data centers.