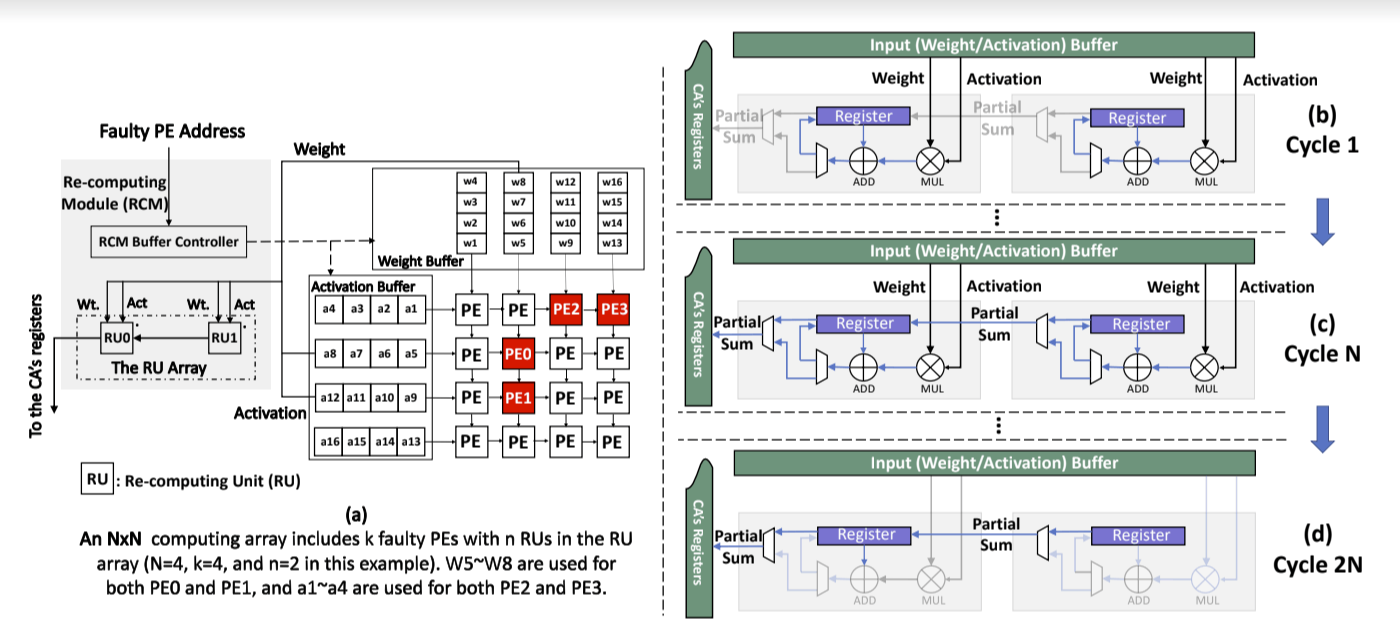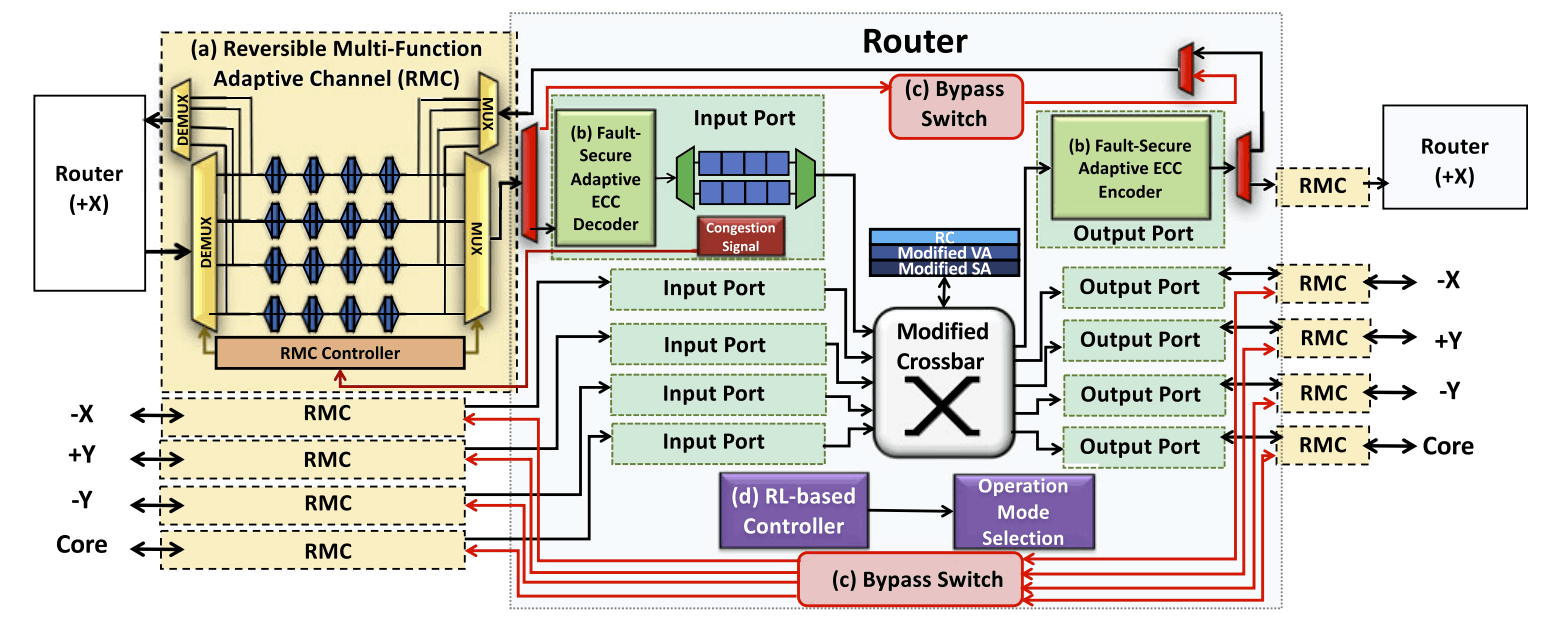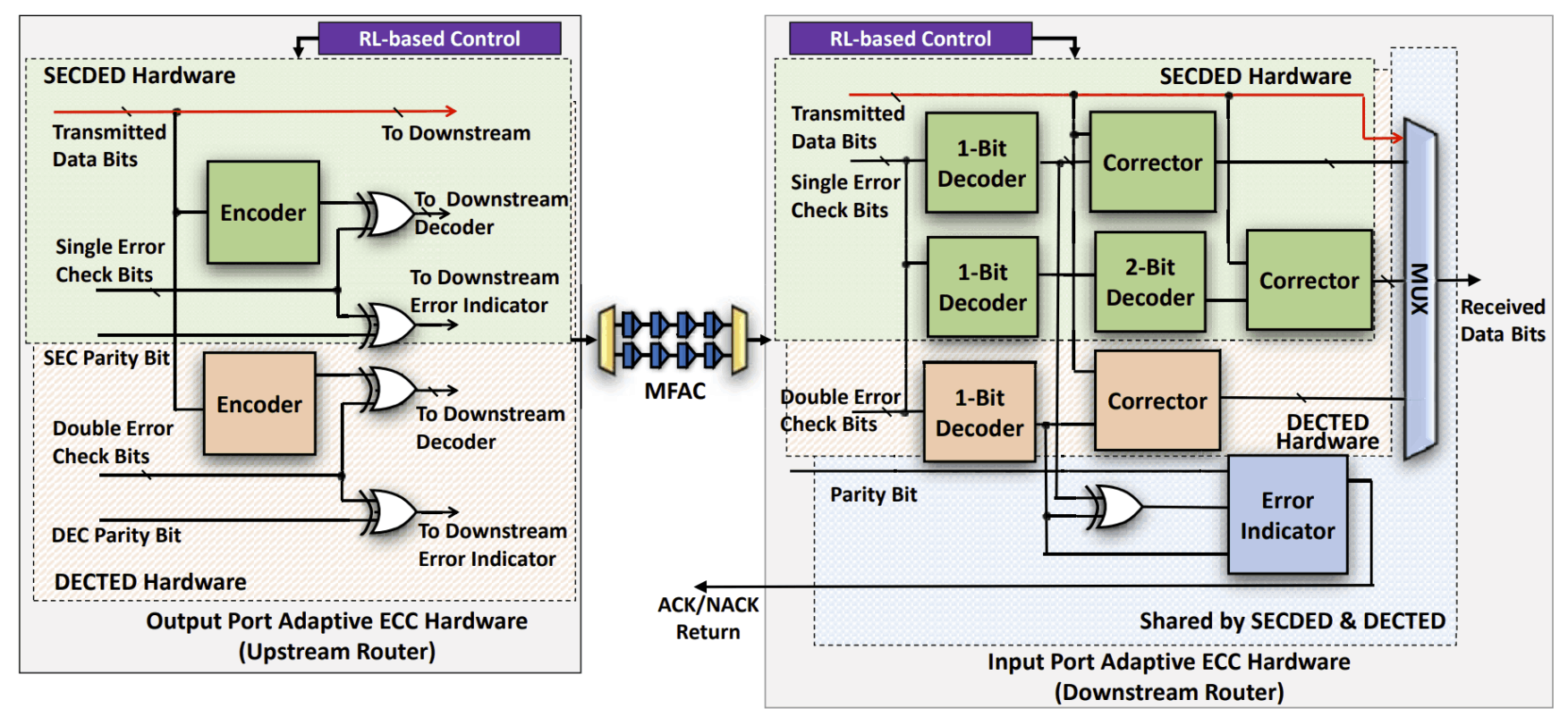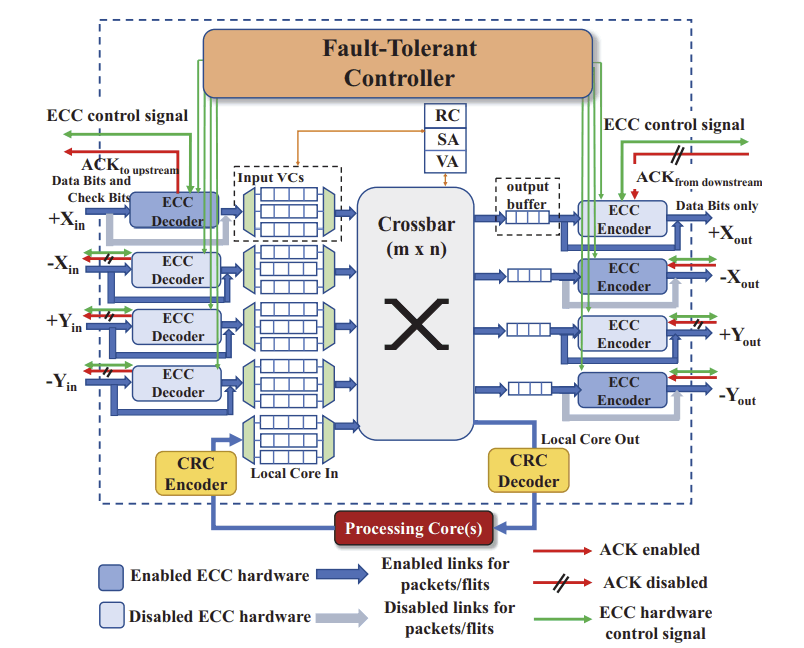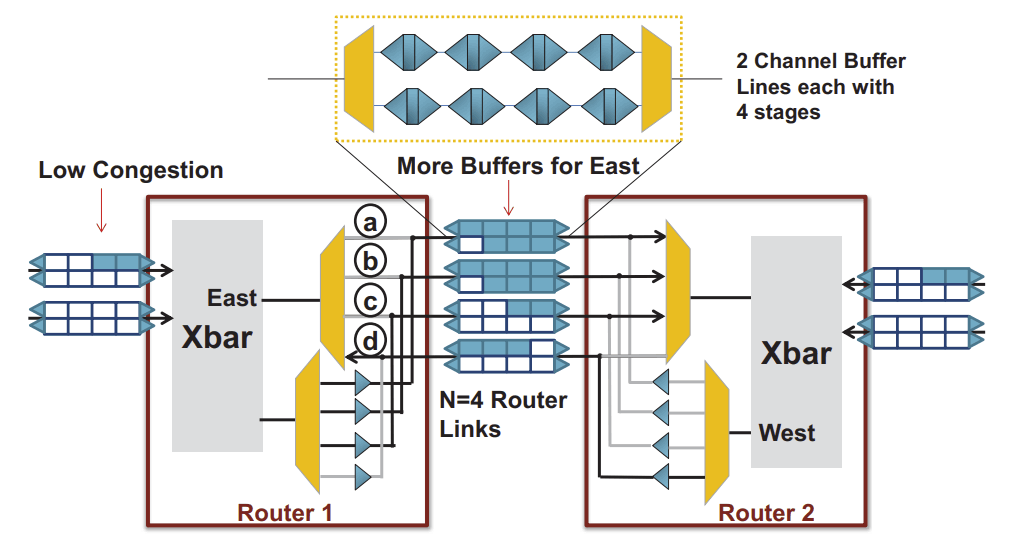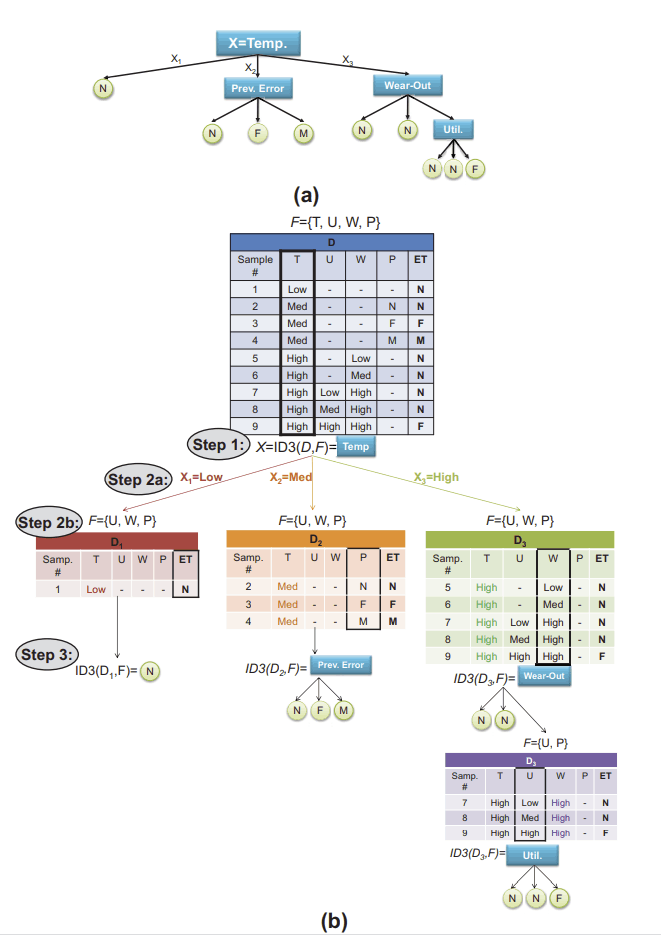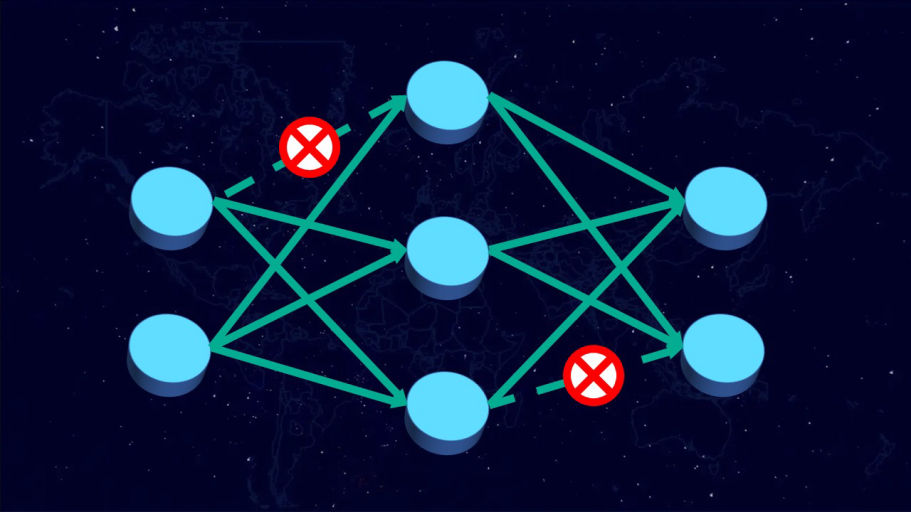
During the past decade, hardware security has become an increasing challenge due to the proliferation of shared resources in modern computer architecture designs. These shared resources can unavoidably allow sensitive data to be leaked to malicious parties through side or covert channels, or be exploited by malicious hardware Trojans (HTs) implanted during design or manufacturing. Side-channel attacks create and monitor disturbances of electronic systems through timing, power, current, and electromagnetic emissions to leak information and covertly transmit data. Hardware Trojans, on the other hand, can manipulate on-chip routing behavior to disrupt communication and degrade performance while evading traditional detection mechanisms. Moreover, the malicious sources behind these hardware-based attacks are hard to detect, since they operate covertly without explicitly transferring data or exposing their traces. In this research task, we comprehensively evaluate the microarchitecture designs of multicore systems and explore their hardware vulnerabilities to both side-channel attacks and hardware Trojan threats. This is followed by the development of efficient countermeasures against those attacks without adversely impacting system performance. The research topics include malicious node detection, secure on-chip data transmission, and learning-based mitigation techniques for both side-channel attacks and hardware Trojans.